
XPath, which expands to XML Path Language, is one of the longstanding standards in terms of web scraping and automation testing. It offers a very powerful way to locate elements within the web page. The XPath expressions also allow you to navigate through the HTML DOM tree using both relative paths and absolute paths.
However, to properly use the functionalities of XPath, you must understand it beyond the basic expressions. For example, you can use it to fine-tune the location of elements, handle dynamic web content, and also increase the flexibility of test automation.
If you are looking to implement all these parameters, this is the perfect blog for you. Here we will discuss the key XPath functions to help you master the expertise in locating web elements with precision.
What is XPath?
Before we start discussing all the complex XPath expressions, let us take a step back and recap the basics of XPath and why it is important for modern web automation testing.
At its core, it is a query language which helps identify parts of an XML or HTML document. In the current market, it is mostly used in web automation tools like Selenium. This is because it helps to locate elements within a page. XPath expressions can locate these elements using various axes, which will include hierarchical relationships like sibling-sibling, parent-child or even across unrelated nodes.
Let us now divert our attention towards the two major types of XPath expressions:
- The absolute XPath expressions will specify the full path from the root node to the target elements. For example, “/html/body/div[1]/div[2]/ul/li[3]”
- On the other hand, relative XPath expressions will use a relative path from any node to find an element within the web application. A perfect example would be “//ul/li[@class=’menu-item’]”
Based on the above explanations, we can conclude that relative XPath is mainly more flexible than absolute XPath. The changes in DOM structure will often break the functionality of absolute paths. XPath functions add another layer of flexibility and power to the testing process for modern web applications.
Why Should You Use XPath Functions ?
Web pages will often contain dynamic elements like elements which can load asynchronously, elements with variable attributes, or even elements that have duplicate properties. XPath functions will provide you with a very sophisticated way to handle these challenges.
Let us now turn our attention toward some of the most important offerings of XPaths that help resolve these problems:
- It will help narrow down the search results based on tests, attribute values, or other dynamic properties within the web page.
- You can also perform pattern matching to target multiple elements with similar attributes within the target web page.
- XPath can traverse complex web structures more efficiently.
- You also have the option to handle case-sensitive and case-insensitive content easily as per your requirements.
- Finally, you can also create more robust and adaptive locators for performing complex test cases within your automation workflows.
Key XPath Functions for Precision in Web Element Location
Let us now turn our attention toward some of the major expressions that you must implement for precision in web element location processes:
1. contains()
This function is one of the most frequently used and one of the most important functions that comes within XPath. It will allow you to perform partial matching of strings. This approach is useful when the attribute value of an element is dynamic or changes slightly during the implementation process. We have also attached the syntax for implementing this function with XPath:
XPath: //tagname[contains(@attribute, ‘partial_value’)]
You can use the above function for handling dynamic elements where the full attribute is not known. It also comes in handy while locating elements with partial text or attribute matching.
2. starts-with()
Similar to the contains() function, the starts-with() function will also help you to locate elements whose attributes or text values start with a particular string. This particular function comes in handy when an element has a prefix, attribute, or content that remains constant throughout the implementation process.
You can use the following syntax to implement this function with XPath:
XPath: //tagname[starts-with(@attribute, ‘prefix’)]
This function becomes especially useful when you are locating elements with dynamically generated prefixes. It will also assist you in efficiently narrowing down search results by targeting the beginning of an attribute value.
3. text()
This function is mainly used to locate elements based on their text content. It will be extremely useful when elements have no unique attributes or when the text itself is the primary distinguishing factor for the locating process. The following snippet will allow you to implement this function with XPath:
XPath: //tagname[text()=’exact_text’]
You can use this function to find elements where the text value is unique. It will also come in handy in situations where other attributes, such as the ID or class, are dynamic or duplicated across multiple other elements.
4. normalize-space()
Modern web content often includes various unnecessary whitespaces. In such a scenario, the normalize-space() function will eliminate the leading and trailing white spaces. This approach will make it easier to match the text elements that may have inconsistent spacing. To implement this function, you simply have to enter the following code snippet in the terminal window:
XPath: //tagname[normalize-space(text())=’normalized_text’]
This function can be useful while you are trying to handle inconsistent wide spaces within your webpage text. It will also help you to improve text robustness when dealing with formatted content like paragraphs or descriptions.
5. position()
This function will return the position of a node in a node-set. This approach will be very useful when you want to look at a specific element among a list of similar other elements. To implement this function within the XPath library, you simply have to enter the following code snippet:
XPath: (//tagname)[position()=n]
Based on the initial definition, we can conclude that it can be useful for handling elements in a repeated position like lists or tables. It is also extremely useful when you are trying to target a specific element in a scenario where only its position in a group is relevant.
6. last()
The last() function will assist you in selecting the last element in a node-set. You can also utilize this tool in situations where the length of a list or number of elements is unknown during the testing or locating process. To implement this function, you simply have to enter the following code snippet in the terminal window:
XPath: (//tagname)[last()]
This function is useful for selecting the last item from dynamically generated content. For example you can consider the most recent post in a list of comments or reviews in the selection process. It will also help you to navigate elements where the last item holds special significance like the final step in a checkout process.
7. substring()
The substring() function will allow you to extract a portion of a string from an attribute or text. You can use this function when only a certain part of the string is important for locating an element on the web page. To implement this function, you just have to enter the following code snippet in the terminal window:
XPath: substring(@attribute, start, length)
This function will be extremely useful in situations where only part of an attribute or text is stable. It will also assist you in locating events by breaking down longer or more complex strings.
Integrating XPath Functions with Cloud Platforms
We recommend the testers to use XPath functions in combination with cloud platforms to handle complex web structures, dynamic elements, and multiple environments efficiently.
To further improve our understanding regarding the implementation of this process, let us consider this step with the example of LambdaTest:
LambdaTest is an AI-powered test orchestration and execution platform that lets you perform manual and automation testing at scale with over 3000 real devices, browsers, and OS combinations. This platform offers easy integration with Selenium WebDriver which supports XPath expressions. You can also use this integration to easily locate elements while running a testing scenario.
The following code snippet demonstrates how you can set up LambdaTest with Selenium for this testing scenario.
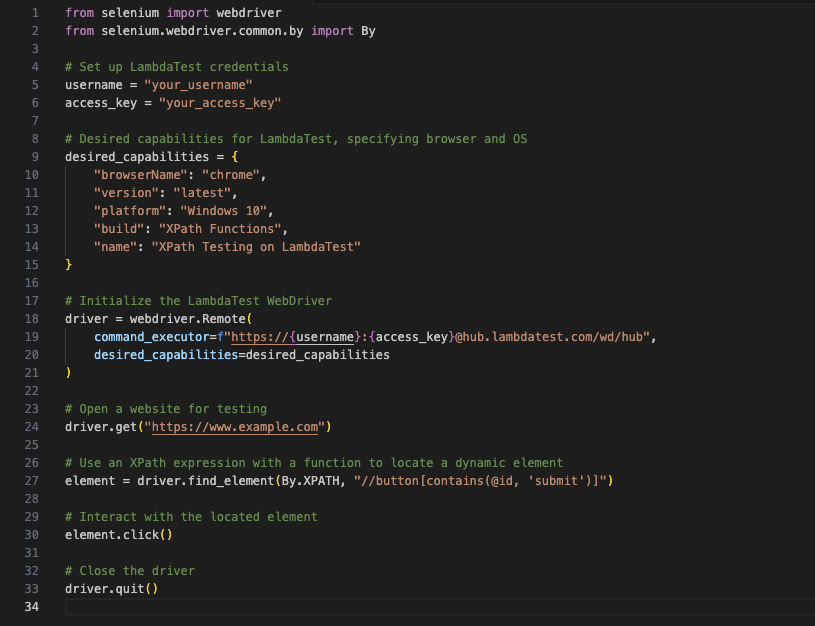
You can also integrate parallel testing with LambdaTest to run multiple tests at the same time across various browser environments. Moreover, combining XPath functions with this testing process will help you ensure that the tests run efficiently without worrying about small DOM differences between browsers.
To further improve our understanding of this testing scenario, we have mentioned a sample code snippet that can help you initiate this step:
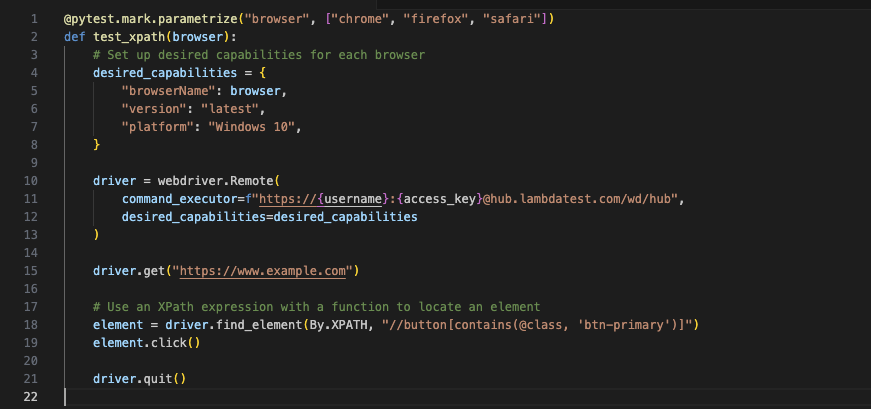
Best Practices for Using XPath Functions
Finally, let us go through some of the best practices that we highly recommend integrating within your XPath functions:
- Although absolute XPath can be useful in certain scenarios, we recommend using relative XPath combined with functions. This is because it will offer more resilience against changes within the DOM structure.
- We recommend the testers to use contains() and starts-with() functions for dealing with elements that have dynamic attribute values. This process becomes especially useful in modern web apps with frameworks like Angular or React.
- It is also important to use position() and last() functions to precisely look at specific elements within the web application. These functions are relevant even if you’re working with multiple similar elements.
- Before you add an XPath expression within your automation test script, it is very important to test it within the browser developer tools. This approach will help you ensure that it works correctly and does not negatively impact the application’s functioning.
- Using an XPathTester tool can help simplify and verify your XPath expressions before integrating them into your tests.
- Finally, we recommend the testers to avoid overcomplicating XPath expressions. For example, although combining multiple functions can be powerful, it can become hard to read and maintain if taken to the extreme level.
The Bottom Line
Based on all the factors that we went through in this article, we can safely conclude that mastering XPath functions is a very important skill for web developers and testers who are aiming to create robust automation scripts. By using all the functions that we mentioned in this article, you can make XPath expressions more flexible and resilient to all the dynamic changes within the web app.
As web elements continue to become more complex, XPath functions will provide the precision to ensure that your automated tests are accurate, efficient, and maintainable. Finally, by using the properties of XPath functions, you can elevate your web development standards. This approach will help ensure that your scripts remain robust and adaptable to all the upcoming technologies in the industry.



